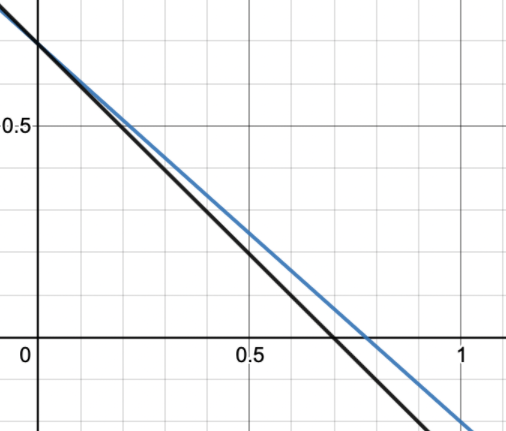
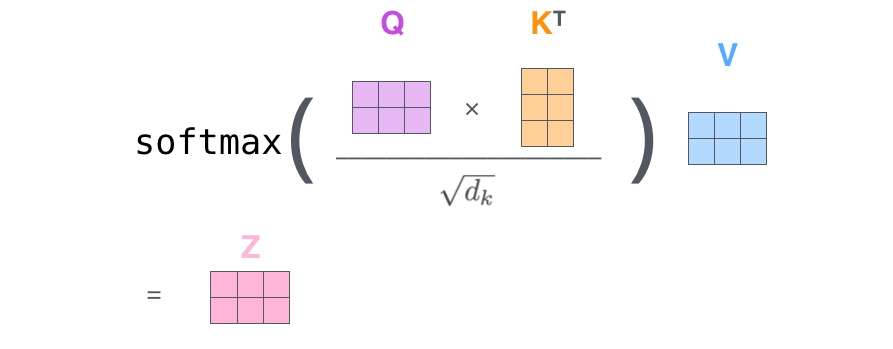关于知识蒸馏温度T的一个简单解释(最优化函数拟合角度) 从最优化角度简单设计了一下softmax的优化目标, 然后通过函数拟合。这篇文章通过更换对softmax进行拟合时的近似函数来从数值上直接解释知识蒸馏温度T对原来数值的影响。 2022-04-17 Miscellaneous #Knowledge Distillation
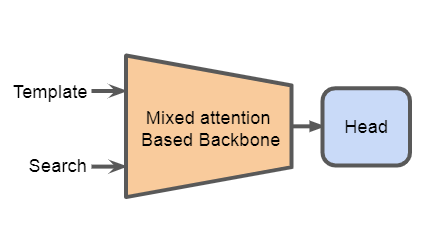
论文阅读:MixFormer: End-to-End Tracking with Iterative Mixed Attention 阅读了一篇使用注意力机制提取并整合target和候选区域特征从而做视觉目标跟踪任务的文章, MixFormer。 2022-03-29 Paper Reading #Transformer #Tracking
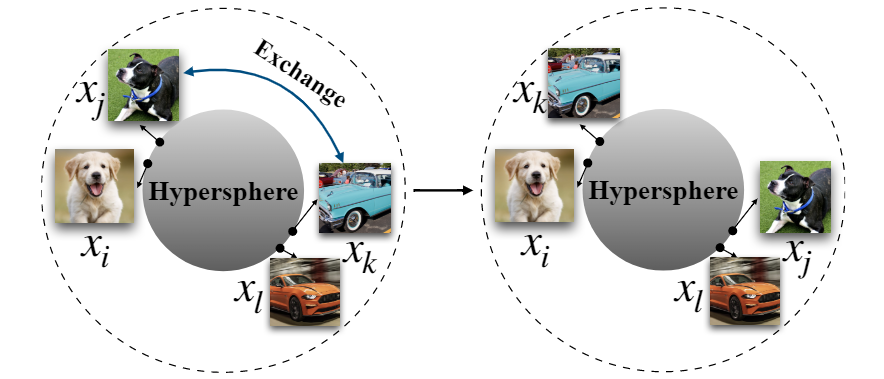
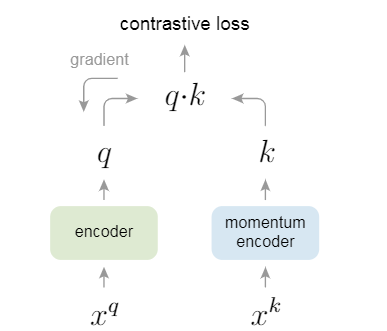
论文阅读:MoCo系列论文解读 最近读了何恺明的MoCo系列论文, 于是写这篇作为总结, 学习了动量方法和实验的一些设置。 2022-03-13 Paper Reading #Contrastive Learning #Momentum #SimCLR
Contrastive Loss 中超参数τ的研究 对比损失 (Contrastive Loss) 中的参数τ是一个神秘的参数, 大部分论文都默认采用较小的值来进行自监督对比学习 (例如 0.05), 但是很少有文章详细讲解参数τ的作用, 本文将详解对比损失中的超参数。 2022-03-05 Contrastive Learning #Contrastive Loss #InfoNCE
论文阅读:Attention Is All You Need 阅读了这篇文章, 进一步学习了 attention 机制, 了解了 Transformer 的架构和 NLP 里的 Q,K,V 概念。 2022-02-24 Paper Reading #Transformer
PyTorch 分布式训练 本文介绍 PyTorch 上进行多机多卡分布式训练的原理和操作方法,以便于训练神经网络时获得显著的性能提升。 2022-02-24 Coding > PyTorch #Distribute #PyTorch
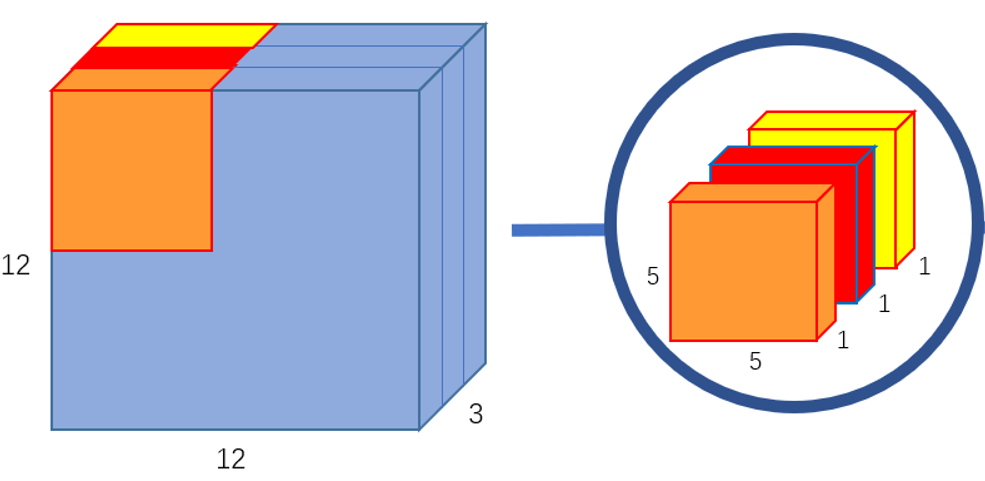
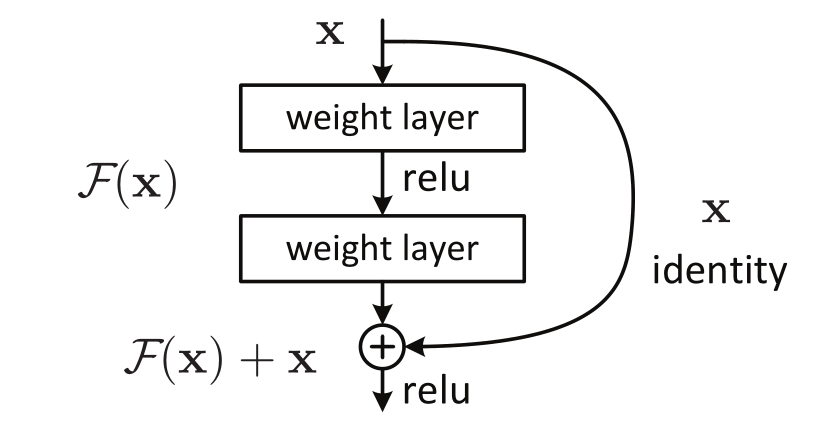
论文阅读:Deep Residual Learning for Image Recognition 阅读了何恺明大佬的文章, 学习了残差的结构, 优化方式, 和原理。通过应用残差网络, 可以训练更深的网络, 同时避免模型退化问题。 2022-02-23 Paper Reading #Residual Block
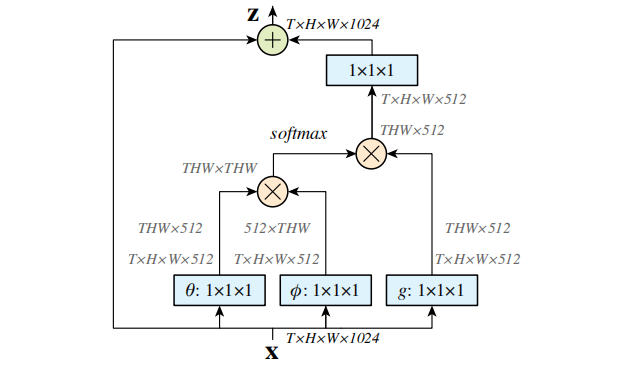
论文阅读:Non-local Neural Networks 想学习一下NLP领域的Self-attention机制但是看了一些文章没看太懂, 于是看了这篇非局部神经网络。Self-attention可以被视为是一种non-local的特殊情况。 2022-02-22 Paper Reading #Attention